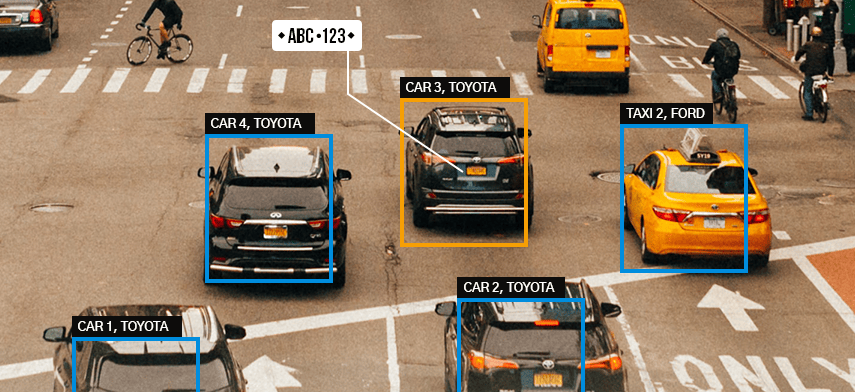
Object Detection Using TensorFlow and Roboflow
Introduction
Object detection is a crucial task in computer vision, allowing machines to identify and locate objects within images. In this tutorial, we’ll walk through the process of building an object detection model using TensorFlow and Roboflow, a platform that simplifies dataset management.
Install TensorFlow Model Garden Package (tf-models-official)
pip install -U tf-models-official
Import Necessary Libraries
import os
import pprint
import tempfile
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from PIL import Image
from six import BytesIO
from urllib.request import urlopen
from official.core import exp_factory
from official.core import task_factory
from official.core import train_lib
from official.vision.ops.preprocess_ops import resize_and_crop_image
from official.vision.dataloaders.tf_example_decoder import TfExampleDecoder
from official.vision.utils.object_detection import visualization_utils
from official.vision.serving import export_saved_model_lib
pp = pprint.PrettyPrinter(indent=4) # Set Pretty Print Indentation
print(tf.__version__) # Check the version of tensorflow used
%matplotlib inline
Dataset Preparation
We start by obtaining a dataset from Roboflow, which contains images and corresponding annotations. The dataset is then split into training and validation sets. We convert these datasets into the TFRecord format, a preferred format for TensorFlow.
Download the Car Number Plates Dataset
robofolow_dataset = tempfile.mkdtemp()
curl -L "https://universe.roboflow.com/ds/DwPgoftzcM?key=2ruB4KoWty" > /tmp/roboflow.zip
unzip -q -o /tmp/roboflow.zip -d {robofolow_dataset}
rm /tmp/roboflow.zip
Generate Train TFRecords
OUTPUT_TF_RECORDS_DIR = tempfile.mkdtemp()
TRAIN_DATA_DIR = f'{robofolow_dataset}/train'
TRAIN_ANNOTATION_FILE_DIR = f'{robofolow_dataset}/train/_annotations.coco.json'
output_tfrecord_train1 = os.path.join(
OUTPUT_TF_RECORDS_DIR, 'train'
)
# Need to provide
# 1. image_dir: where images are present
# 2. object_annotations_file: where annotations are listed in json format
# 3. output_file_prefix: where to write output converted TFRecords files
python -m official.vision.data.create_coco_tf_record --logtostderr \
--image_dir={TRAIN_DATA_DIR} \
--object_annotations_file={TRAIN_ANNOTATION_FILE_DIR} \
--output_file_prefix={output_tfrecord_train1} \
--num_shards=2
Generate Validation TFRecords
VALID_DATA_DIR = f'{robofolow_dataset}/valid'
VALID_ANNOTATION_FILE_DIR = f'{robofolow_dataset}/valid/_annotations.coco.json'
output_tfrecord_valid1 = os.path.join(
OUTPUT_TF_RECORDS_DIR, 'valid'
)
# Need to provide
# 1. image_dir: where images are present
# 2. object_annotations_file: where annotations are listed in json format
# 3. output_file_prefix: where to write output converted TFRecords files
python -m official.vision.data.create_coco_tf_record --logtostderr \
--image_dir={VALID_DATA_DIR} \
--object_annotations_file={VALID_ANNOTATION_FILE_DIR} \
--output_file_prefix={output_tfrecord_valid1} \
--num_shards=1
Display a Batch of Train Dataset
tf_example_decoder = TfExampleDecoder()
def show_batch(raw_records, num_of_examples):
plt.figure(figsize=(20, 20))
use_normalized_coordinates=True
min_score_thresh = 0.30
for i, serialized_example in enumerate(raw_records):
plt.subplot(1, 3, i + 1)
decoded_tensors = tf_example_decoder.decode(serialized_example)
image = decoded_tensors['image'].numpy().astype('uint8')
scores = tf.ones(shape=(len(decoded_tensors['groundtruth_boxes'])))
visualization_utils.visualize_boxes_and_labels_on_image_array(
image,
decoded_tensors['groundtruth_boxes'].numpy(),
decoded_tensors['groundtruth_classes'].numpy().astype('int'),
scores,
category_index=category_index,
use_normalized_coordinates=use_normalized_coordinates,
max_boxes_to_draw=200,
min_score_thresh=min_score_thresh,
agnostic_mode=False,
instance_masks=None,
line_thickness=4)
plt.imshow(image)
plt.axis('off')
plt.title(f'Image-{i+1}')
plt.show()
buffer_size = 20
num_of_examples = 3
raw_records = tf.data.TFRecordDataset(
tf.io.gfile.glob(OUTPUT_TF_RECORDS_DIR + '/train*')).shuffle(
buffer_size=buffer_size).take(num_of_examples)
show_batch(raw_records, num_of_examples)
Model Configuration
For our object detection model, we choose the RetinaNet architecture with a ResNet backbone. We configure the model, specifying the number of classes, anchor sizes, and input dimensions. Transfer learning is employed by initializing the model with pre-trained weights.
exp_config = exp_factory.get_exp_config('retinanet_resnetfpn_coco')
Download the ResNet-50 Backbone
ckpt_dir = tempfile.mkdtemp()
wget "https://storage.googleapis.com/tf_model_garden/vision/retinanet/retinanet-resnet50fpn.tar.gz" -P "/tmp/"
tar -xvzf "/tmp/retinanet-resnet50fpn.tar.gz" -C {ckpt_dir}
rm "/tmp/retinanet-resnet50fpn.tar.gz"
Training Configuration
BATCH_SIZE = 8
epochs = 5
IMG_SIZE = 640
steps_per_epoch = NUM_TRAIN_EXAMPLES // BATCH_SIZE
validation_steps = NUM_VAL_EXAMPLES // BATCH_SIZE
num_train_steps = steps_per_epoch * epochs
warmup_steps = int(0.1 * num_train_steps)
initial_learning_rate = 0.01
warmup_learning_rate = 0.5 * initial_learning_rate
# Runtime configuration
exp_config.runtime.mixed_precision_dtype = 'bfloat16'
# exp_config.runtime.num_gpus = 1
# Task Level configuration
exp_config.task.init_checkpoint = os.path.join(ckpt_dir, "ckpt-33264")
exp_config.task.init_checkpoint_modules = 'backbone'
exp_config.task.freeze_backbone = True
exp_config.task.annotation_file = ''
# Model configuration
exp_config.task.model.num_classes = 3
exp_config.task.model.anchor.anchor_size = 4.0
exp_config.task.model.anchor.aspect_ratios = [0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 4.0, 5.0]
exp_config.task.model.input_size = [IMG_SIZE, IMG_SIZE, 3]
# Train data configuration
exp_config.task.train_data.input_path = os.path.join(OUTPUT_TF_RECORDS_DIR, 'train*')
exp_config.task.train_data.global_batch_size = BATCH_SIZE
exp_config.task.train_data.dtype = 'float32'
# Validation data configuration
exp_config.task.validation_data.input_path = os.path.join(OUTPUT_TF_RECORDS_DIR, 'val*')
exp_config.task.train_data.global_batch_size = BATCH_SIZE
exp_config.task.validation_data.dtype = 'float32'
# Trainer configuration
exp_config.trainer.checkpoint_interval = steps_per_epoch
exp_config.trainer.optimizer_config.warmup.linear.warmup_steps = steps_per_epoch
exp_config.trainer.optimizer_config.warmup.linear.warmup_learning_rate = warmup_learning_rate
exp_config.trainer.optimizer_config.learning_rate.type = 'cosine'
exp_config.trainer.optimizer_config.learning_rate.cosine.decay_steps = num_train_steps
exp_config.trainer.optimizer_config.learning_rate.cosine.initial_learning_rate = initial_learning_rate
exp_config.trainer.train_steps = num_train_steps
exp_config.trainer.validation_steps = validation_steps
exp_config.trainer.validation_interval = steps_per_epoch
exp_config.trainer.steps_per_loop = steps_per_epoch
exp_config.trainer.summary_interval = steps_per_epoch
pp.pprint(exp_config.as_dict())
{ 'runtime': { 'all_reduce_alg': None,
'batchnorm_spatial_persistent': False,
'dataset_num_private_threads': None,
'default_shard_dim': -1,
'distribution_strategy': 'mirrored',
'enable_xla': False,
'gpu_thread_mode': None,
'loss_scale': None,
'mixed_precision_dtype': 'bfloat16',
'num_cores_per_replica': 1,
'num_gpus': 0,
'num_packs': 1,
'per_gpu_thread_count': 0,
'run_eagerly': False,
'task_index': -1,
'tpu': None,
'tpu_enable_xla_dynamic_padder': None,
'use_tpu_mp_strategy': False,
'worker_hosts': None},
'task': { 'allow_image_summary': False,
'annotation_file': '',
'differential_privacy_config': None,
'export_config': { 'cast_detection_classes_to_float': False,
'cast_num_detections_to_float': False,
'output_intermediate_features': False,
'output_normalized_coordinates': False},
'freeze_backbone': True,
'init_checkpoint': '/tmp/tmp4sm_f79o/ckpt-33264',
'init_checkpoint_modules': 'backbone',
'losses': { 'box_loss_weight': 50,
'focal_loss_alpha': 0.25,
'focal_loss_gamma': 1.5,
'huber_loss_delta': 0.1,
'l2_weight_decay': 0.0001,
'loss_weight': 1.0},
'max_num_eval_detections': 100,
'model': { 'anchor': { 'anchor_size': 4.0,
'aspect_ratios': [ 0.5,
1.0,
1.5,
2.0,
2.5,
3.0,
4.0,
5.0],
'num_scales': 3},
'backbone': { 'resnet': { 'bn_trainable': True,
'depth_multiplier': 1.0,
'model_id': 50,
'replace_stem_max_pool': False,
'resnetd_shortcut': False,
'scale_stem': True,
'se_ratio': 0.0,
'stem_type': 'v0',
'stochastic_depth_drop_rate': 0.0},
'type': 'resnet'},
'decoder': { 'fpn': { 'fusion_type': 'sum',
'num_filters': 256,
'use_keras_layer': False,
'use_separable_conv': False},
'type': 'fpn'},
'detection_generator': { 'apply_nms': True,
'max_num_detections': 100,
'nms_iou_threshold': 0.5,
'nms_version': 'v2',
'pre_nms_score_threshold': 0.05,
'pre_nms_top_k': 5000,
'return_decoded': None,
'soft_nms_sigma': None,
'tflite_post_processing': { 'max_classes_per_detection': 5,
'max_detections': 200,
'nms_iou_threshold': 0.5,
'nms_score_threshold': 0.1,
'normalize_anchor_coordinates': False,
'omit_nms': False,
'use_regular_nms': False},
'use_class_agnostic_nms': False,
'use_cpu_nms': False},
'head': { 'attribute_heads': [],
'num_convs': 4,
'num_filters': 256,
'share_classification_heads': False,
'use_separable_conv': False},
'input_size': [640, 640, 3],
'max_level': 7,
'min_level': 3,
'norm_activation': { 'activation': 'relu',
'norm_epsilon': 0.001,
'norm_momentum': 0.99,
'use_sync_bn': False},
'num_classes': 3},
'name': None,
'per_category_metrics': False,
'train_data': { 'apply_tf_data_service_before_batching': False,
'autotune_algorithm': None,
'block_length': 1,
'cache': False,
'cycle_length': None,
'decoder': { 'simple_decoder': { 'attribute_names': [ ],
'mask_binarize_threshold': None,
'regenerate_source_id': False},
'type': 'simple_decoder'},
'deterministic': None,
'drop_remainder': True,
'dtype': 'float32',
'enable_shared_tf_data_service_between_parallel_trainers': False,
'enable_tf_data_service': False,
'file_type': 'tfrecord',
'global_batch_size': 8,
'input_path': '/tmp/tmpd67ub1pe/train*',
'is_training': True,
'parser': { 'aug_policy': None,
'aug_rand_hflip': True,
'aug_scale_max': 1.2,
'aug_scale_min': 0.8,
'aug_type': None,
'match_threshold': 0.5,
'max_num_instances': 100,
'num_channels': 3,
'skip_crowd_during_training': True,
'unmatched_threshold': 0.5},
'prefetch_buffer_size': None,
'seed': None,
'sharding': True,
'shuffle_buffer_size': 10000,
'tf_data_service_address': None,
'tf_data_service_job_name': None,
'tfds_as_supervised': False,
'tfds_data_dir': '',
'tfds_name': '',
'tfds_skip_decoding_feature': '',
'tfds_split': '',
'trainer_id': None,
'weights': None},
'use_coco_metrics': True,
'use_wod_metrics': False,
'validation_data': { 'apply_tf_data_service_before_batching': False,
'autotune_algorithm': None,
'block_length': 1,
'cache': False,
'cycle_length': None,
'decoder': { 'simple_decoder': { 'attribute_names': [ ],
'mask_binarize_threshold': None,
'regenerate_source_id': False},
'type': 'simple_decoder'},
'deterministic': None,
'drop_remainder': True,
'dtype': 'float32',
'enable_shared_tf_data_service_between_parallel_trainers': False,
'enable_tf_data_service': False,
'file_type': 'tfrecord',
'global_batch_size': 8,
'input_path': '/tmp/tmpd67ub1pe/val*',
'is_training': False,
'parser': { 'aug_policy': None,
'aug_rand_hflip': False,
'aug_scale_max': 1.0,
'aug_scale_min': 1.0,
'aug_type': None,
'match_threshold': 0.5,
'max_num_instances': 100,
'num_channels': 3,
'skip_crowd_during_training': True,
'unmatched_threshold': 0.5},
'prefetch_buffer_size': None,
'seed': None,
'sharding': True,
'shuffle_buffer_size': 10000,
'tf_data_service_address': None,
'tf_data_service_job_name': None,
'tfds_as_supervised': False,
'tfds_data_dir': '',
'tfds_name': '',
'tfds_skip_decoding_feature': '',
'tfds_split': '',
'trainer_id': None,
'weights': None}},
'trainer': { 'allow_tpu_summary': False,
'best_checkpoint_eval_metric': '',
'best_checkpoint_export_subdir': '',
'best_checkpoint_metric_comp': 'higher',
'checkpoint_interval': 122,
'continuous_eval_timeout': 3600,
'eval_tf_function': True,
'eval_tf_while_loop': False,
'loss_upper_bound': 1000000.0,
'max_to_keep': 5,
'optimizer_config': { 'ema': None,
'learning_rate': { 'cosine': { 'alpha': 0.0,
'decay_steps': 610,
'initial_learning_rate': 0.01,
'name': 'CosineDecay',
'offset': 0},
'type': 'cosine'},
'optimizer': { 'sgd': { 'clipnorm': None,
'clipvalue': None,
'decay': 0.0,
'global_clipnorm': None,
'momentum': 0.9,
'name': 'SGD',
'nesterov': False},
'type': 'sgd'},
'warmup': { 'linear': { 'name': 'linear',
'warmup_learning_rate': 0.005,
'warmup_steps': 122},
'type': 'linear'}},
'preemption_on_demand_checkpoint': True,
'recovery_begin_steps': 0,
'recovery_max_trials': 0,
'steps_per_loop': 122,
'summary_interval': 122,
'train_steps': 610,
'train_tf_function': True,
'train_tf_while_loop': True,
'validation_interval': 122,
'validation_steps': 8,
'validation_summary_subdir': 'validation'}}
Training
Create the Task object (tfm.core.base_task.Task) from the config_definitions.TaskConfig.
The Task object has all the methods necessary for building the dataset, building the model, and running training & evaluation. These methods are driven by tfm.core.train_lib.run_experiment.
model_dir = tempfile.mkdtemp()
with distribution_strategy.scope():
task = task_factory.get_task(exp_config.task, logging_dir=model_dir)
model, eval_logs = train_lib.run_experiment(
distribution_strategy=distribution_strategy,
task=task,
mode='train_and_eval',
params=exp_config,
model_dir=model_dir)
Exporting the Model
Once satisfied with the model’s performance, we export it for serving using TensorFlow’s SavedModel format. This step prepares the model for deployment in various applications.
export_dir = './model/'
export_saved_model_lib.export_inference_graph(
input_type='image_tensor',
batch_size=1,
input_image_size=[IMG_SIZE, IMG_SIZE],
params=exp_config,
checkpoint_path=tf.train.latest_checkpoint(model_dir),
export_dir=export_dir)
Inference on New Images
We demonstrate how to use the trained model for inference on new images. The model identifies objects in these images, and we visualize the results, showcasing the model’s ability to detect and classify objects accurately.
Load the exported model
imported = tf.saved_model.load(export_dir)
model_fn = imported.signatures['serving_default']
def load_image_into_numpy_array(path):
"""Load an image from file into a numpy array.
Puts image into numpy array to feed into tensorflow graph.
Note that by convention we put it into a numpy array with shape
(height, width, channels), where channels=3 for RGB.
Args:
path: the file path to the image
Returns:
uint8 numpy array with shape (img_height, img_width, 3)
"""
image = None
if(path.startswith('http')):
response = urlopen(path)
image_data = response.read()
image_data = BytesIO(image_data)
image = Image.open(image_data)
else:
image_data = tf.io.gfile.GFile(path, 'rb').read()
image = Image.open(BytesIO(image_data))
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(1, im_height, im_width, 3)).astype(np.uint8)
def build_inputs_for_object_detection(image, input_image_size):
"""Builds Object Detection model inputs for serving."""
image, _ = resize_and_crop_image(
image,
input_image_size,
padded_size=input_image_size,
aug_scale_min=1.0,
aug_scale_max=1.0)
return image
Inference on Validation Images
input_image_size = (IMG_SIZE, IMG_SIZE)
plt.figure(figsize=(20, 20))
min_score_thresh = 0.4 # Change minimum score for threshold to see all bounding boxes confidences.
val_ds = tf.data.TFRecordDataset(
tf.io.gfile.glob(exp_config.task.validation_data.input_path + '*'))
for i, serialized_example in enumerate(val_ds.shuffle(20).take(3)):
plt.subplot(1, 3, i+1)
decoded_tensors = tf_example_decoder.decode(serialized_example)
image = build_inputs_for_object_detection(decoded_tensors['image'], input_image_size)
image = tf.expand_dims(image, axis=0)
image = tf.cast(image, dtype = tf.uint8)
image_np = image[0].numpy()
result = model_fn(image)
visualization_utils.visualize_boxes_and_labels_on_image_array(
image_np,
result['detection_boxes'][0].numpy(),
result['detection_classes'][0].numpy().astype(int),
result['detection_scores'][0].numpy(),
category_index=category_index,
use_normalized_coordinates=False,
max_boxes_to_draw=200,
min_score_thresh=min_score_thresh,
agnostic_mode=False,
instance_masks=None,
line_thickness=4)
plt.imshow(image_np)
plt.axis('off')
plt.show()
Conclusion
In conclusion, this tutorial covered the end-to-end process of building an object detection model using TensorFlow and Roboflow. From dataset preparation to model configuration, training, and deployment, you now have a foundation to create your own custom object detection solutions.